
在图片和视频中的人脸匹配(人脸识别)是一项非常有用的技术,尤其是随着近来自带摄像功能的手机普及。通过对人脸的五官识别,我们可以用实现自己的眼球追踪,照相中的表情(包括微笑,眨眼等)识别,或者在照相/摄影中添加一些有趣的涂鸦元素,可以是一撇八字胡,一副太阳镜,或是按上一个猪鼻子 :)
熟悉Android的同学一定会善意地提醒我,在Android的SDK中已经包含了 android.hardware.Camera.FaceDetectionListener 和 android.media.FaceDetector 两个类,实现了对图片和Camera预览的人脸识别,没必要再重新发明一遍轮子了吧。实际上,这两个API的作用是在图片或者照相机预览中检测人脸的位置,不能匹配到五官,因此还不完全满足我们的需要。不过好在有了这两个API,我们可以从照片或者照相机预览中方便,快速地找到人脸的位置,然后进行下一步的精确匹配。
接下来我们主要会描述这个所谓的“精确匹配“是如何进行的(如果没有特别指出,文中提到的“人脸匹配”都是指的这个“精确匹配”过程),如果是对“从图片中找到人脸的位置”感兴趣的话,可以参考android的相关源代码,或者在网上搜索”haar adaboost”或”viola-jones”了解算法详情。
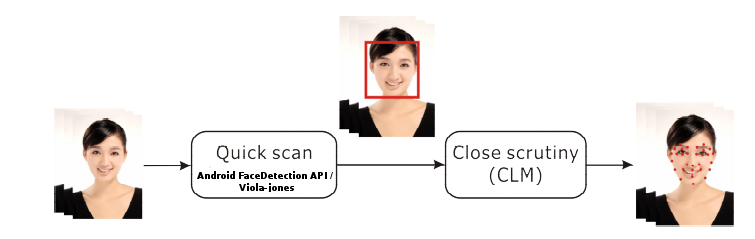 人脸匹配的2个步骤
人脸匹配的2个步骤Constrained Local Model(CLM) 限制局部模型
如标题所说,我们采用了CLM进行人脸匹配。但在描述具体算法之前,先考虑下我们面对的问题:
给定一个矩形图片,确定图片包括了一张人脸,如何找出眼睛,鼻子和嘴巴的位置,并确定脸部的轮廓。
对于一个普通人来说,这样的判断是显而易见的(但是对于计算机来说,面对的只是0和1的数据,这个过程就没那么简单了)。如果硬是要把这个判断过程分解一下的话,可能会包含两个部分:
- 我们知道脸上每个部分的长相:脸(轮廓)是一个上下长,左右宽的椭圆形。眉毛是黑色的粗线,眼睛是左右长,上下宽的椭圆,中间有黑色的球状等等。如果没有这些具体的知识,那么我们就不可能从图片中找到五官的具体位置。这里,我们把各部分的长相称作Local Model
- 除了各部分的长相之外,我们还知道这些部分之间的位置关系,鼻子位于脸的正中,在它的上方左右两边是眼睛,眼睛上方是眉毛,鼻子的正下方是嘴巴。这样的位置关系,我们把它叫作约束(Constrains).约束的好处在于,我们不必在图中的每个位置去匹配单个器官,只需在约束给定的位置周围(Local Region)进行查找匹配即可
实际上,这个过程就是CLM算法的大致解释:每个Local Model在全局的位置约束(Constrains)之下,寻找最佳的匹配。
既然了解了什么是CLM,我们也清楚了,要顺利执行CLM,我们需要两类信息,一是脸上每个部分的长相,称作Local Model或者Patch Model, 它们被用来在目标图片中寻找最佳匹配;二是每个Patch可能出现的位置,它们被称作Shape Model,我们用Shape Model来约束每个Patch的搜寻范围。这两类信息合在一起被称作CLM Model.
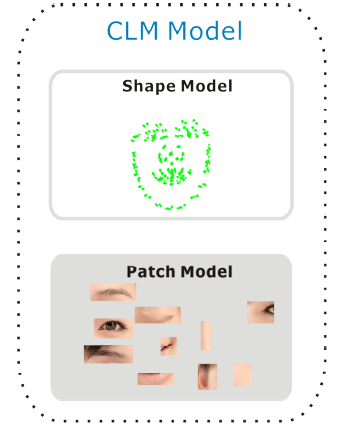
一般说来,完整的CLM系统包含:
- CLM模型的建立
- 使用CLM模型在目标图片中查找
模型的建立采用机器学习的方式生成,一般在PC或服务器上运行,用Matlab或者OpenCV写成的学习程序检索(学习)指定的训练样本,最后生成CLM数据模型,CLM Model通常是xml,json或者binary data。之后将CLM Model和与之适应的CLM 搜索程序放到目标机器(手机)上执行。
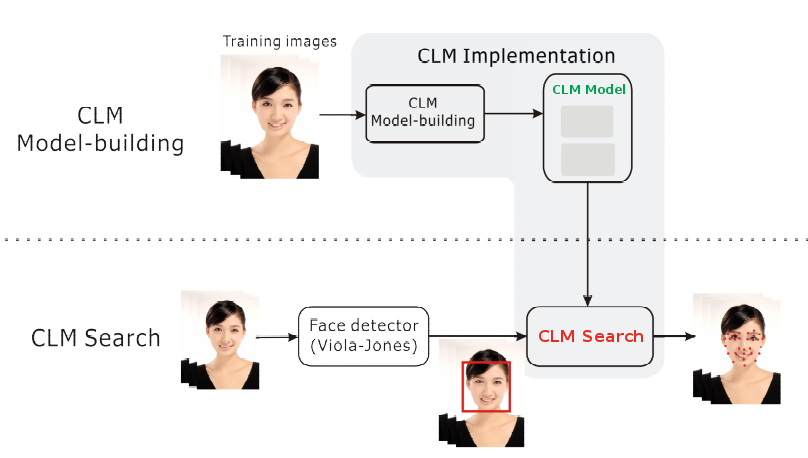
在我们目前的实现中,暂时仅实现了手机端的CLM Search的部分, 模型部分只是简单地拷贝了Github上已经训练好的数据,该模型的训练样本来自MUCT数据库。这个数据库的优点是免费且数据量大(约5000张照片),缺点是不含戴眼镜的样本,且表情不够丰富;这样,当我们在预测时遇到戴眼镜的,或者是表情极度扭曲的图片时,匹配会不够精确。如果想获得更好的匹配效果,也不排除将来采用其他数据库,我们自己训练CLM模型的做法。
CLM Model的建立
这一节我们更详细讨论CLM,包括Patch Model和Shape Model具体的内容,它们的建立过程(简略)以及在搜索过程中如何使用它们。
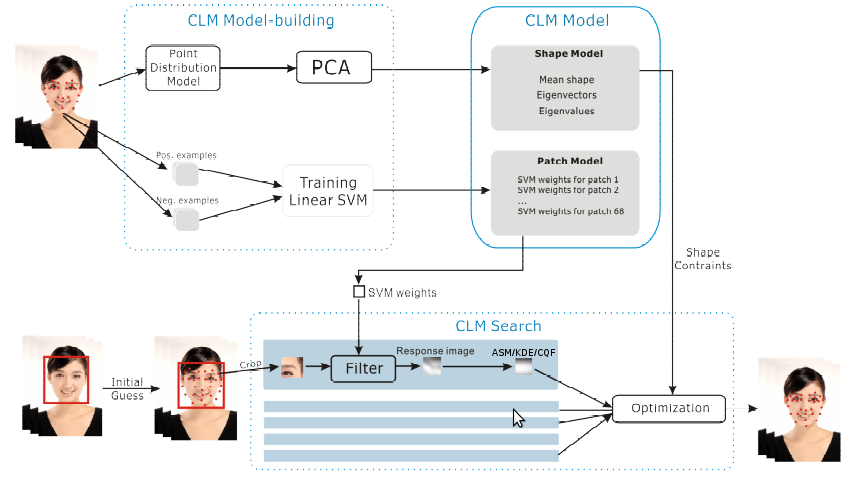
Patch Model
和我们简单地把人脸简单分成五官不同,计算机更适合较小而容易分辨的特征区域(特征点)。最理想的特征区域是那些“边缘位置”,比如眼角,嘴角,眼球,眉毛,嘴唇等等。选取这些位置作为特征点可以更好地避免光照条件带来的影响。具体选取哪些位置作为特征点是数据库(训练样本)的定义,在我们当前所用的MUCT数据库中,共有71个特征点。

对于每个特征点,机器学习的算法通过“看”每张照片上相应的区域(我们用的是 11×11 pixel大小的区域),生成Patch Model,定义出每个特征点应该长的什么样子。在我们的CLM Model中,采用的是”线性内核支持向量机”*(Linear-SVM)的学习方式,训练的图片源是8bit的灰阶图**(这也意味着我们匹配的目标图片必须转为8bit灰阶图才可以工作)。生成的Patch Model包含了71个SVM分类器(SVM Filters)。

* SVM(Support Vector Machine)支持向量机是机器学习中监督式学习(不理解也没关系)的常用工具之一。经常用来建立逻辑分类器。常用内核包括“线性核”和“高斯核”,一般来说,线性核速度更快,高斯核拟合数据更好(尤其对于高阶特征)。线性核生成的结果是一组权重(weights+bias),用该权重预测目标数据时得到的结果表示目标为真的可能,值越大则为真的可能越高。一般认为>=0.5为真,反之为假。关于“支持向量机”更多的详情可以到网上查找。
** 训练样本和预测的目标数据必须是格式一致的。在auduno的数据模型中除了用灰阶图生成的Patch Model之外还提供了用sobel和lbp图训练的结果。后两种图可以更好地减少光照/肤色的影响。
Shape Model
Shape Model描述了脸部每个特征点的位置以及它们可能的位移。建立Shape Model的过程是首先计算出Mean Shape(平均脸), 即每个特征点的中心位置(期望)在哪里。然后用每个样本减去Mean Shape, 得到的就是不同的脸/姿势/表情造成的变化(Shape Variant):比如宽额头,眯眼睛,长鼻子。。。
很可能你会认为这样的变化是无穷的,想像一下世界上有几十亿人口,没有2个是长得完全一样的,更不用说人脸的肌肉可以摆出成千上万种表情了。但是,如果我们把这些变化进行分类的话,比如,宽脸型/窄脸型,男性/女性,高加索人/亚洲人,高兴/伤心。。。我们就可以大致可以用这些分类的组合来描述一张人脸。
于是,在Shape Model中包括了平均脸(Mean Shape),脸“变化“的维度(EigenVector)和“变化”的系数(EigenValue)三种信息。EigenVector和EigenValue的名字来自于线性代数。 这里所说的变化维度和系数实际来自于对所有脸的协方差矩阵(Covariance Matrix)求解特征向量(EigenVector)和特征值(EigenValue)**
* PCA(Principal Component Analysis)主成份分析是机器学习中非监督方式学习(不理解也没关系)的一种常用算法。PCA的作用是对数据进行降维,减少存储以及运算的工作量,和有损压缩有点类似。
** 不理解也没关系,想搞明白的话看下PCA。
使用CLM Model进行查找
CLM查找的过程并不算十分复杂,下面是分解的流程图,大致分为 1.初始匹配(Initial Guess)-> 2.图片片段截取(Crop Patches)-> 3.计算反馈图(Response Image) -> 4.顶点选取(Select/Calc Peak) -> 5.计算当前轮廓(Calc Current Shape) -> 6.收敛测试(Convergence Test)
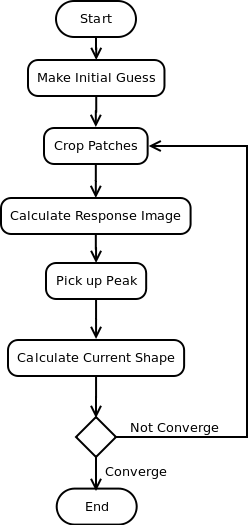
接下来我们一步步观察实现的细节。
初始匹配
初始匹配并不要求拟合是精确的,只是要求“尽可能准确”。由于在第一步”脸部位置检测”中只能检查到人脸的位置,而没有其他信息,我们一般都采用“平均脸”进行拟合。